As we roll towards the end of the year data engineering as expected does have some changes, but now everyone wants to see how Generative AI intersects with everything. The fits are not completely natural, as Generative AI like Chat GPT is more NLP type systems, but there are a few interesting cases to keep an eye on. Also Apache Iceberg is one to watch now there is more first class Amazon integration.
Retrieval Augmented Generation (RAG) Pattern
One of the major use cases for data engineers to understand for Generative AI is the retrieval augmented generation (rag) pattern.
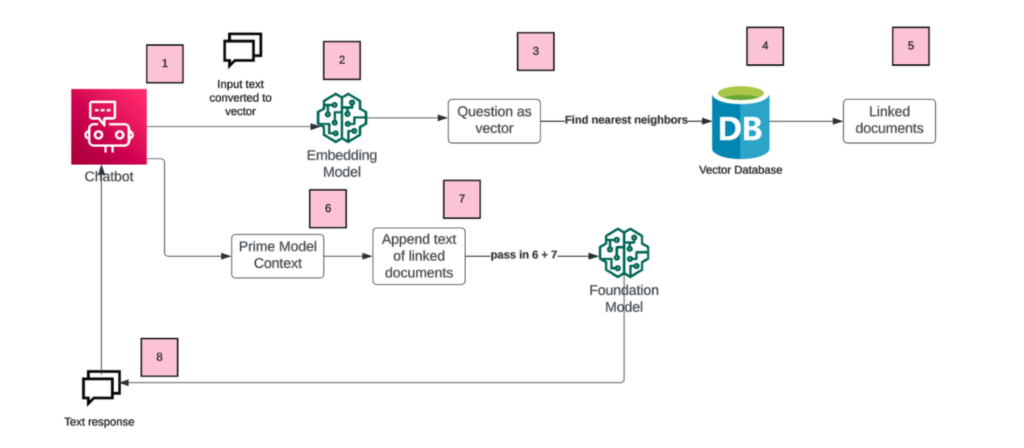
There are quite a few articles on the web articulating this such as
- https://www.pinecone.io/learn/retrieval-augmented-generation/
- https://medium.com/@rubyroidlabs/how-to-build-an-ai-chatbot-with-ruby-on-rails-and-chatgpt-9a48f292c37c
What is important to realize is that Generative AI is only providing the light weight wrapper interface to your system. The RAG paradigm was created to help address context limitations by vectorizing your document repository and using some type of nearest neighbors algorithm to find the relevant data and passing it back to a foundation model. Perhaps LLMS with newer and larger context windows (like 100k context) may address these problems.
At the end of the data engineers will be tasked more with chunking, and vectorizing back end systems, and debates probably will emerge in your organization whether you want to roll out your own solution or just use a SAAS to do it quickly.
Generative AI for Data Engineering?
One of the core problems with generative AI is eventually it will start hallucinating. I played around with asking ChatGPT to convert CSV to JSON, and it worked for about the first 5 prompts, but by the 6th prompt, it started to make up JSON fields which never existed.
Things I kind of envision in the future is the ability to use LLMs to stitch parts of data pipelines concerning data mapping and processing. But at the moment, it is not possible because of this.
There is some interesting research occurring where a team has put a finite state machine (FSM) with LLMs to create deterministic JSON output. I know that might not seem like a big deal, but if we can address deterministic outcomes of data generation, it might be interesting to look at
https://github.com/normal-computing/outlines
So far use cases we see day to day are
1. Engineers using LLMs to help create SQL or Spark code scaffolds
2. Creation of synthetic data – basically pass in a schema and ask an LLM to generate a data set for you to test
3. Conversion of one schema to another schema-ish. This kind of works, but buyer beware
Apache Iceberg
Last year our organization did a proof of concept with Apache Iceberg, but one of the core problems, is that Athena and Glue didn’t have any native support, so it was difficult to do anything.
However on July 19, 2023 AWS quietly released an integration with Apache Iceberg & Athena into production
Since then, AWS has finally started to treat Iceberg as a first class product with their documentation and resources
- https://aws.amazon.com/blogs/big-data/perform-upserts-in-a-data-lake-using-amazon-athena-and-apache-iceberg/ (a bit older)
- https://aws.amazon.com/what-is/apache-iceberg/
Something to keep track of is that the team which founded Apache Iceberg, founded a company called tabular.io which provides hosted compute for Apache Iceberg workloads. Their model is pretty interesting because what you do is give Tabular access to your S3 buckets and they will deal with ingestion, processing, and file compaction for you. They even can point to DMS CDC logs, and create SCD Type 1, and query SCD Type 2 via time travel via a couple clicks which is pretty fancy to me.
However if you choose to roll things out yourself, expect to handle engineering efforts similar to this
https://tabular.io/blog/cdc-merge-pattern/
The Open Source Table Format Wars Continue
One of the core criticisms of traditional datalakes the difficulty to perform updates or deletes against them. With that, we have 3 major players in the market for transactional datalakes.
| Platform | Link | Paid Provider |
|---|---|---|
| Databricks | https://docs.databricks.com/en/delta/index.html | Via hyperscaler |
| Apache Hudi | https://hudi.apache | https://onehouse.ai/ |
| Apache Iceberg | https://iceberg.apache.org/ | https://tabular.io/ |
What’s the difference between these 3 you say? Well, 70% of the major features are similar, but there are some divergent features
Also don’t even consider AWS Governed Tables and focus on the top 3 if you have these use cases.
Redshift Serverless Updates
There has been another major silent update that now Redshift Serverless only requires 8 RPUs to provision a cluster. Before it was 32 RPUs which was ridiculously high number
8 RPUs x 12 hours x 0.36 USD x 30.5 days in a month = 1,054.08 USD
Redshift Serverless cost (monthly): 1,054.08 USD
Ra3.xlplus – 1 node
792.78 USD
So as you can see provisioned is still cheaper, but look into Serverless if
· You know your processing time of the cluster will be 50% idle
· You don’t want to deal with the management headaches
· You don’t need a public endpoint
DBT
Data Built Tool (dbt), has really been gaining a lot of popularity at the moment. It is kind of weird for this pendulum to be swinging back and forth as originally many years ago we had these super big SQL scripts running on data warehouses. That went out of fashion, but now here we are
A super interesting thing that got released is a dbt-glue adapter.
https://pypi.org/project/dbt-glue/
That means you can now run dbt SQL processing on Athena now
For those new to dbt feel free to check this out
https://dbt.picturatechnica.com/
https://corpinfollc.atlassian.net/wiki/spaces/APS/pages/119138643968195/DBT+ETL+getdbt.com
Glue Docker Image
A kind of a weird thing, but I recently saw the ability to launch Glue as a local docker image. I haven’t personally tried this, but it is interesting
https://github.com/juanAmayaRamirez/docker_compose_glue4.0
https://aws.amazon.com/blogs/big-data/developing-aws-glue-etl-jobs-locally-using-a-container/
Zero ETL Intrigue
This is kind of an old feature, but Amazon rolled out in preview a Zero ETL method of MySQL 8.x to Redshift
This is pretty intriguing meaning SCD Type 1 views should be replicated without doing any work of putting data through a datalake. However it is still in preview, so I can’t recommend it until it goes into general release.