Here is this quarter’s state of data engineering newsletter. There is only a little chat about AI this time, and a focus on Open Table Formats, the Apache Iceberg Rest Spec, Open Table Format updates, and new updates in the Amazon Data Engineering ecosystem.
Prompt Engineering – Meta Analysis Whitepaper
One of my favorite AI podcasts, Latent Space, recently featured Sander Schulhoff, one of the authors of a comprehensive research paper on prompt engineering. This meta-study reviews over 1,600 published papers, with co-authors from OpenAI, Microsoft, and Stanford.
[podcast]
https://www.latent.space/p/learn-prompting
[whitepaper]
https://arxiv.org/abs/2406.06608
The whitepaper is an interesting academic deep dive into prompting, and how to increase the quality of it through exemplars (examples provided into an LLM), but not providing too many (more than 20 hurts quality), and strange things like Minecraft agents are tools to understand how this ecosystem works.
Other practical tips are given where asking for data in JSON and XML generally is more accurate and results formatted based of the LLM’s training data is better. That does kind of lead to a problem if you don’t know what the training data is based off
It provides a wide range of tools outside of the two common ones we use the most – chain of thought – which is a multi turn conversation, and retrieval augmented generation (RAG).
We can expect in the next couple of years where LLMs themselves will integrate these workflows so we don’t care about it anymore, but if you want to squeak out some better performance this paper is worth reading.
Open Table Format Wars – Continued
As a quick refresher, the history of data engineering kind of goes like this in 30 seconds
- 1980s – big data warehouses exist. SQL is lingua franca
- 2000s – Apache Hadoop ecosystem comes out to address limitations of data warehouses to cope with size and processing
- 2010s – Datalakes emerge where data is still in cloud storage (E.G. Amazon S3)
- 2020ish – Datalakehouses or Transactional Datalakes come out to address limitations of Datalakes capability to be ACID compliant
- 2023 – Consensus emerges over the term Open Table Format (OTF) with three contenders
- Apache Hudi
- Databrick Deltalake
- Apache Iceberg
- Mid 2024s
- June 3, 2024 – Snowflake announces Polaris catalog support for Apache Iceberg
- June 4, 2024 – Databricks buys Tabular (thereby bringing in the founders of Apache Iceberg)
Historically, we see a major shift in technology about every 20 years, with older systems being overhauled to meet new paradigms. Consider the companies that fully embraced Apache Hadoop in the 2000s—they’re now in the process of rebuilding their systems. Right now we are in the middle of the maturing of open table formats.
Data has always kind challenging to deal with because the nature of data is messy, and moving data from one system to another seems simple, but is quite a bit of work as we know most ETL rarely is straight forward when taking into accounts SLAs, schema changes, data volumes, etc.
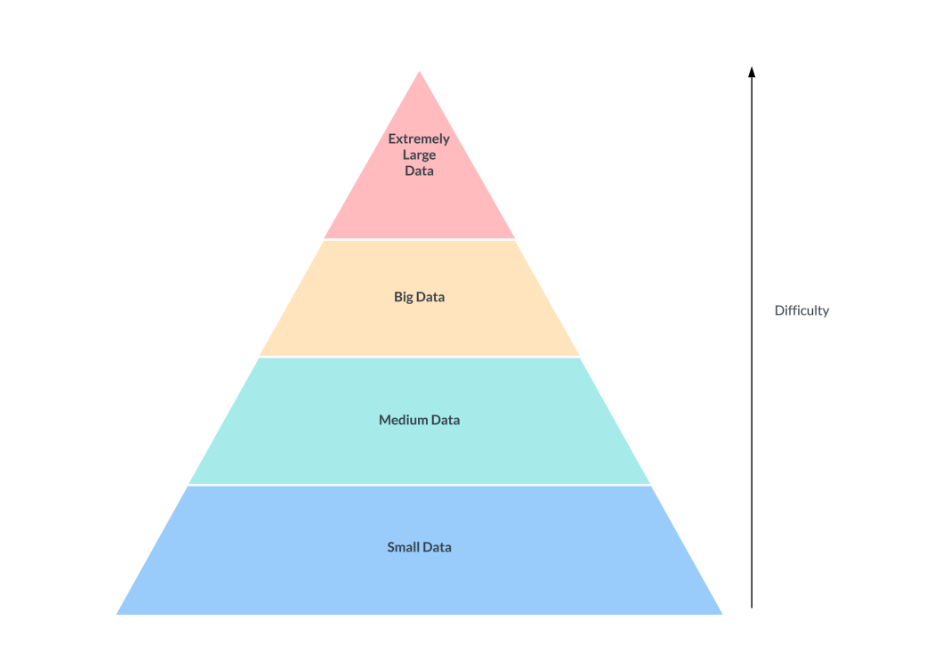
OTFs really matter for us when we deal with big data, and especially for extremely large data (think Uber or Netflix size data). Databases usually can handle the blue and green without problem, but break at the yellow and red.
When working with your data platform, these are key questions you should be asking to help in refining your technology stack.
- How much data is being processed (are we talking hundreds of gigabytes, terabytes, or petabytes?)
- What is the SLA the data needs to be queried?
- What is the existing data foot print in your organization (are you using a lot of MySQL, Microsoft, etc)
- Does the organization have the capability to own the engineering effort of an OTF platform?
- Do any of the customer’s data sources work for ZeroETL (like Salesforce, Aurora MySQL/Postgres, RDS?)
- Is the customer already using Databricks, Hudi, Snowflake, Iceberg, Redshift, or Big Query?
The Future: Interoperability via the Apache Iceberg Catalog API
Apache Iceberg, which emerged from Netflix recently has recently been making a lot of news lately. From the acquisition of Tabular (basically the guys who founded Iceberg), to Snowflake open sourcing the Polaris catalog, to Databricks support in private preview, many signs are pointing to a more cross compatible future if certain conditions are met.
In this article
https://www.snowflake.com/en/blog/introducing-polaris-catalog/
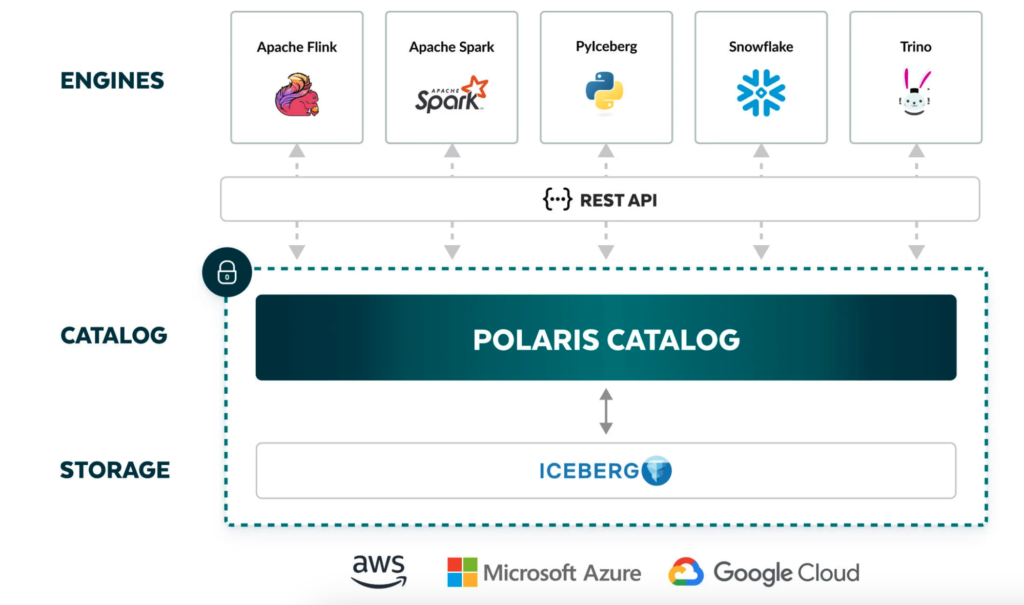
There is a pretty important diagram where it shows cross compatibility of AWS, Azure, and Google Cloud. We aren’t here yet, but if all 3 vendors move towards implementing the Apache Iceberg HTTP Catalog API spec, that means cross federated querying will be possible.
I’m hopeful, because ETL’ing data from one place to another place has always been a huge hassle. This type of future really opens up interesting workloads where compute really can be separate even from your cloud.
Everything is a little strange to me, because moving towards the future really isn’t a technology problem, but more of a political one if each cloud choose to move that direction. We are getting signs, but I would say by this time next year, we will learn the intentions of all players. Meanwhile, stay tuned.
New emerging technology: DuckDB
DuckDB was created in 2018 and is a fast in-process analytical database. There is a hosted version called MotherDuck, which is based off a serverless offering. DuckDB takes a different approach where you can run analysis on a large data set either via a CLI or your favorite programming language. The mechanisms are slightly different where the compute runs closer to your application itself.
Article: Running Iceberg and Serverless DuckDB in AWS
https://www.definite.app/blog/cloud-iceberg-duckdb-aws
In this article, DuckDB can query Iceberg tables stored in S3. Also, as an alternative it describes deploying DuckDB in a serverless environment using ECS with custom containers via HTTP requests.
In the future, I expect AWS to take more notice and integrate DuckDB in the ecosystem in the next couple of years.
ChatGPT even has a DuckDB analyst ready
https://chatgpt.com/g/g-xRmMntE3W-duckdb-data-analyst
Use Cases:
- Say you have a lot of log data in EC2. Typically, you would load it into S3 and query via Athena. Instead you could load the data in EC2, and then load a DuckDB instance there where you can query it without penalty for exploration
- Preprocessing and pre-cleaning of user-generated data for machine learning training
- Any type of system that previously used SQLite
- Exploration of any data sets if it is on your laptop – this one is a no brainer.
— Iceberg Updates:
[Article]: The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables
TLDR: Iceberg now supports snapshot and orphan file removal
https://aws.amazon.com/blogs/big-data/the-aws-glue-data-catalog-now-supports-storage-optimization-of-apache-iceberg-tables/
Amazon previously tackled the issue of small file accumulation in Apache Iceberg tables by introducing automatic compaction. This feature consolidated small files into larger ones, improving query performance and reducing metadata overhead, ultimately optimizing storage and enhancing analytics workloads.
Building on this, Amazon has now released a new feature in AWS Glue Data Catalog that automatically deletes expired snapshots and removes orphan files. This addition helps control storage costs and maintain compliance with data retention policies by cleaning up unnecessary data, offering a more complete solution for managing Iceberg tables efficiently.
[Feature]: Accelerate query performance with Apache Iceberg statistics on the AWS Glue Data Catalog
TLDR: If you want faster SLA in Iceberg tables, run the table statistics feature for a potential of 24 –> 80% in improvement in query time
Column-level statistics are a method for enhancing the query performance of Iceberg tables in Amazon Redshift Spectrum and Athena. These statistics are based on the Puffin file format and allow query engines to optimize SQL operations more effectively. You can enable this feature via the AWS Console or by running an AWS Glue job. According to the performance data in the blog post, improvements range from 24% to 83%, simply by running a job to store metadata.
Summary:
- Use this if you have large datasets and need consistent query performance. Small datasets may not benefit enough to justify the effort.
- Be aware of the overhead involved in running and maintaining statistics jobs.
- Since data will likely change over time, you should set up automated jobs to periodically regenerate the statistics to maintain performance gains. While manual effort is required now, this feature could be more integrated into the platform in the future.
[Article]: Petabyte-Scale Row-Level Operations in Data Lakehouses
Authors: Apache Foundation, Apple Employees, Founder of Apache Iceberg
TLDR: If you need to do petabyte scale row level changes, read this paper.
https://www.vldb.org/pvldb/vol17/p4159-okolnychyi.pdf
We rarely have run into the scale of needed to run petabyte row level changes, but it details a strategy with these techniques
| Technique | Explanation | Hudi Equivalent | Databricks Equivalent |
| Eager Materialization | Rewrites entire data files when rows are modified; suitable for bulk updates. | Copy-on-Write (COW) | Data File Replacement |
| Lazy Materialization | Captures changes in delete files, applying them at read time; more efficient for sparse updates. | Merge-on-Read (MOR) | Delete Vectors |
| Position Deletes | Tracks rows for deletion based on their position within data files. | Delete Vectors | |
| Equality Deletes | Deletes rows based on specific column values, e.g., row ID or timestamp. | Delete Vectors | |
| Storage-Partitioned Joins | Eliminates shuffle costs by ensuring data is pre-partitioned based on join keys. | Low Shuffle MERGE | |
| Runtime Filtering | Dynamically filters out unnecessary data during query execution to improve performance. | Runtime Optimized Filtering | |
| Executor Cache | Caches delete files in Spark executors to avoid redundant reads and improve performance. | ||
| Adaptive Writes | Dynamically adjusts file sizes and data distribution at runtime to optimize storage and prevent skew. | ||
| Minor Compaction | Merges delete files without rewriting the base data to maintain read performance. | Compaction in MOR | |
| Hybrid Materialization | Combines both eager and lazy materialization strategies to optimize different types of updates. |
The paper also half reads as a marketing paper for Iceberg, but the interesting aspect is that half of the authors are from Apple. One of the authors of that paper also made this video on how Apache Iceberg is used at Apple.
Video:
https://www.youtube.com/watch?v=PKrkB8NGwdY
[Article]: Faster EMR 7.1 workloads for Iceberg
TLDR: EMR 7.1 runs faster on its customized Spark runtime onEC2
This article essentially serves as marketing for Amazon EMR, but it also demonstrates the product team’s commitment to enhancing performance with Apache Iceberg. It’s a slightly curious comparison, as most users on AWS would likely already be using EMR rather than managing open-source Spark on EC2. Nevertheless, the article emphasizes that EMR’s custom Spark runtime optimizations are significantly faster than running open-source Spark (OSS) on EC2.
- Optimizations for DataSource V2 (dynamic filtering, partial hash aggregates).
- Iceberg-specific enhancements (data prefetching, file size-based estimation).
- Better query planning and optimized physical operators for faster execution.
- Integration with Amazon S3 for reduced I/O and data scanning.
- Java runtime improvements for better memory and garbage collection management.
- Optimized joins and aggregations, reducing shuffle and join overhead.
- Increased parallelism and efficient task scheduling for better cluster utilization.
- Improved resource management and autoscaling for cost and performance optimization.
[Article]: Using Amazon Data Firehose to populate Iceberg Tables
TLDR: Use this technique if you might need Iceberg tables from the raw zone for streaming data and you need ACID guarantees
https://www.tind.au/blog/firehose-iceberg/
Recently, a sharp-eyed developer spotted an exciting new feature in a GitHub Changelog: Amazon Data Firehose now has the ability to write directly to Iceberg tables. This feature could be hugely beneficialfor anyone working with streaming data and needing ACID guarantees in their data lake architecture.
Warning: This feature isn’t production-ready yet, but it’s promising enough that we should dive into how it works and how it simplifies the data pipeline.
: An Interesting Future: Example of Iceberg being queried from Snowflake and Databricks
Randy Pitcher from Databricks shows an example how an Iceberg table created in Databricks is queried with Snowflake. As mentioned earlier, the chattering is not all vendors are fully implemented the Catalog API spec (yet), but once this gets mature in 2026-ish, expect the ability to query data across cloud to be possible.
Redshift Updates
Major updates for Zero ETL
- [Feature] Redshift Zero ETL Available for Salesforce – TLDR: If you need to move data from Salesforce to Redshift, try this first
- [Feature] – Redshift Zero ETL support Amazon RDS – This is a big change as only Amazon Aurora was previously supported
- [Feature] Amazon Redshift Serverless now supports higher base capacity of 1024 Redshift Processing Units
https://aws.amazon.com/about-aws/whats-new/2024/09/amazon-redshift-serverless-capacity-1024-processing-units/ - [Feature ] -Optimize your workloads with Amazon Redshift Serverless AI-driven scaling and optimization
- If you want to experiment with cost/performance widgets in Redshift Serverless
All Other AWS Updates:
- [S3] Amazon S3 now supports conditional writes. We will see how this is integrated into OTF libraries
- [Glue] Introducing AWS Glue Data Quality anomaly detection
- https://aws.amazon.com/blogs/big-data/introducing-aws-glue-data-quality-anomaly-detection/
- Use Glue to check for data anomalies
- https://aws.amazon.com/blogs/big-data/introducing-aws-glue-data-quality-anomaly-detection/
- [Glue] Introducing AWS Glue usage profiles for flexible cost control
- https://aws.amazon.com/blogs/big-data/introducing-aws-glue-usage-profiles-for-flexible-cost-control/
- With this technique, you can put constraints on worker types and workers. I don’t think it 100% solves the cost overrun problem, but it is a start
- https://aws.amazon.com/blogs/big-data/introducing-aws-glue-usage-profiles-for-flexible-cost-control/
- [Glue] Introducing job queuing to scale your AWS Glue workloads
- https://aws.amazon.com/blogs/big-data/introducing-job-queuing-to-scale-your-aws-glue-workloads/
- This enables Glue jobs to be run in a queue if your jobs are failing due to high concurrency issues
- https://aws.amazon.com/blogs/big-data/introducing-job-queuing-to-scale-your-aws-glue-workloads/
- [LakeFormation] Announcing fine-grained access control via AWS Lake Formation with EMR Serverless
- https://aws.amazon.com/about-aws/whats-new/2024/07/fine-grained-access-control-aws-lake-formation-emr-serverless/
- Lake Formation is now caught up to be compatible with EMR Serverless
- https://aws.amazon.com/about-aws/whats-new/2024/07/fine-grained-access-control-aws-lake-formation-emr-serverless/
Other
- [Video]: Modern data architecture at Peloton with Apache Hudi
- https://www.linkedin.com/events/7235419044852424705/comments/
- [Article] about the Snowflake, Databricks rivalary
- History of data engineering, with some brutal stabs on the failures of Apache Hadoop, and how the future is probably more SQL-ish
- OpenAI now allows structured JSON outputs. It is a small move, but we’ll see how far deterministic outputs can be pushed in these systems.
- Netflix released yet another data orchestration framework