Data engineering is a field I would categorize as a subspecialty of software engineering. It shares the same concerns as software engineering—scalability, maintainability, and other “-ilities”—but its primary focus is on data. It’s a unique discipline because data is inherently messy, and as a result, no standard enterprise framework has emerged to dominate the space—and perhaps it never will.
The complexity of a data project can often be measured by the variety and nature of its data sources. For example, a project involving high-volume Internet of Things (IoT) data is vastly different from one dealing with a structured database modeled with Slowly Changing Dimensions (SCD) Type 1.
Data projects generate value by transforming data. Sometimes, simply joining two datasets can uncover new insights. In other cases, cleansing data helps provide clearer metrics for the C-suite to make decisions. In nearly all cases, we are fully aware of the data sources being ingested and monitor them closely for changes, as modifications can impact upstream pipelines.
That’s where Large Language Models (LLMs) start to feel a bit strange. Unlike traditional data projects where the sources are known and controlled, with LLMs—especially frontier models like ChatGPT or Anthropic—we don’t have true visibility into the training data. If someone asked me to build a data project without transparency into the underlying data sources, I’d be very cautious.
The Washington Post attempted to extrapolate what’s in some frontier models by analyzing Google’s C4 dataset:
We can probably assume that most LLMs have read everything publicly visible on the internet—blogs, Reddit, YouTube transcripts, Wikipedia, and so on. The bigger question is whether they’ve read copyrighted books—and, if so, how can we even know?
A while back, I was quite obsessed with making tofu from scratch. The process involved making my own soy milk, then coagulating it with Nigari (a magnesium chloride solution made from seawater). I sourced Nigari locally from Vancouver Island, where the manufacturer gave some tips on how to make it. After many attempts and watching tofu videos on YouTube many times, I finally got a recipe down.
Recently, I had a craving to make Tau Foo Fah, a silky tofu dessert popular across Asia. Unlike Japanese tofu, this version uses a different coagulant—gypsum and cornstarch. The most traditional method I’ve seen involves dissolving the coagulant in water, pouring hot soy milk over it from a height, and letting it set. My results were always inconsistent, so I turned to ChatGPT
In the ChatGPT iOS app, I must have accidentally triggered the “deep research” feature—so instead of querying the regular model, I used a deep research credit. The model suggested the following method.
Heat soy milk to ~185°F (85°C).
Dissolve gypsum + cornstarch in a bit of water.
Pour hot soy milk into the coagulant mix in a mason jar (don’t stir too much).
Place jar on trivet in Instant Pot with water (pot-in-pot method).
Steam on Low for 10 mins → natural release 10–15 mins.
Let it rest undisturbed before opening.
For the sake of experimentation, I tried two approaches in the Instant Pot:
1. I mixed the coagulants in cold soy milk (1% corn starch, .74% gypsum, 100% soymilk), put a cap on a mason jar and steamed it on high for 10 minutes in an instant pot
2. Did what ChatGPT suggested with heating it to 185° F
The results were vastly different. The ChatGPT method didn’t set properly. Looking closer at the deep research citations, I realized most were blogs, and the model had likely built its answer on those foundations. It also seemed to confuse traditional tofu-making techniques with those specific to Tau Foo Fah.
This experience got me thinking more about the importance of data sources and data lineage when using LLMs. Here are a couple questions that take a data centric approach to thinking about them.
1. Do you know what data sources are being referenced in the LLM?
It sounds basic, but it’s critical. LLMs are black boxes in many respects. Just as we wouldn’t integrate unknown data into a pipeline without thorough vetting, we shouldn’t treat LLM outputs as reliable without understanding what they’re based on.
2. Does the prompt you’re asking have high-quality representation in the model’s training data?
It helps to step back and consider the quality and coverage of data within the problem space. For coding-related queries, I assume the quality is high—thanks to well-defined languages grammars, and extensive examples on Stack Overflow and Reddit.
Other well-represented domains likely include medicine and law, given the large corpus of reliable reference material available.
But in areas like food, I’ve learned not to rely on ChatGPT as an authoritative source. Many great recipes are locked behind non-digitized books or restricted datasets that LLMs can’t legally access.
3. Are you able to see data source citations in your answer?
When using a general model like GPT-4o, answers are often returned without citations. That leaves the burden of validation on you—the user.
For low-stakes questions like “What kind of plant is this?”, a wrong answer is annoying, but not disastrous. But if you ask, “How much revenue did we generate last month?” and use the response to make business decisions without verifying the source, the risk increases significantly.
Medical questions are even riskier. Making a health decision based on uncited LLM output is problematic.
Google’s NotebookLM stands out here. You can upload your own PDFs (e.g., data sources), and the model provides footnoted citations linking back to the original documents—much more traceable and reliable.
4. Are you an expert in the domain you’re querying?
A senior software engineer might use ChatGPT to refine a coding solution, while a junior engineer may dangerously implement answers without understanding them.
In general, we need to be cautious about accepting LLM responses at face value. It’s tempting to delegate too much thinking to the machine, but we must not bypass our own analytical skills as we inevitably integrate these tools into our workflows.
There is a lot of chatter about 2025 being the year of agentic frameworks. To me, this means a system in which a subset can allow AI models to take independent actions based on their environment, typically interacting with external APIs or interfaces.
The terminology around this concept is still evolving, and definitions may shift in the coming months—similar to the shifting discussions around Open Table Formats. Below are some key takeaways from recent discussions on agentic systems:
Agents can take actions allowed by a given environment
Agents can be potentially dangerous if given the ability to perform write actions
Agent workflows can potentially be very expensive if not constrained (EG excessive token usage)
When writing traditional software, it’s helpful to think in terms of determinism. In probability theory:
P(1) represents an outcome that is guaranteed to occur (100%).
P(0) represents an outcome that will never occur (0%).
Similarly, code is deterministic—given the same input, it will always produce the same output. Business rules drive execution, either directly through the code or abstracted into configuration files.
However, agents break this determinism by introducing an element of decision-making and uncertainty. Instead of executing predefined logic, agents operate within a framework that allows for flexible responses based on real-time data. This can be powerful, as it enables systems to handle edge cases without explicitly coding for them. But it also raises evaluation challenges—how do we determine if an agent is performing well when its behavior isn’t fully predictable?
Taking a data engineering perspective on this, I think usefulness of agents will be directly proportional to the quality of the data sources available for an agent.
ChatGPT and similar LLMs have been useful primarily because they have likely ingested the entire Internet. Whether this has been done in full compliance with copyright laws is a separate issue.
More structured domains, such as coding, have thrived due to the constraints imposed by programming languages, as these languages are inherently built upon specific grammatical rules.
When customers add data sources to their agentic frameworks I can only imagine a lot of data cleansing and structuring will have to be done to make these systems successful.
Every year, there are tons of announcements, and you can catch a recap of all the new services in this 126 slide PDF from AWS courtesy of community days.
Another major launch during re:Invent was Sagemaker Unified Studio. Capabilities include:
Amazon SageMaker Unified Studio (public preview): use all your data and tools for analytics and AI in a single development environment.
Amazon SageMaker Lakehouse: unify data access across Amazon S3 data lakes, Amazon Redshift, and federated data sources.
Data and AI Governance: discover, govern, and collaborate on data and AI securely with Amazon SageMaker Catalog, built on Amazon DataZone.
Model Development: build, train, and deploy ML and foundation models, with fully managed infrastructure, tools, and workflows with Amazon SageMaker AI.
Generative AI app development: Build and scale generative AI applications with Amazon Bedrock.
SQL Analytics: Gain insights with the most price-performant SQL engine with Amazon Redshift.
Data Processing: Analyze, prepare, and integrate data for analytics and AI using open-source frameworks on Amazon Athena, Amazon EMR, AWS Glue, and Amazon Managed Workflows for Apache Airflow (MWAA).
In the data field, there are two options, build vs buy. AWS traditionally follows the build approach, offering tools for developers to create their own platforms. However, operationalizing data platforms is complex, and competitors like Databricks and Snowflake offer faster onboarding workflows with vertically integrated components.
SageMaker Lakehouse shows potential as it attempts to bridge the gap between build and buy solutions. It offers robust management features within its UI, including CI/CD workflows similar to GitHub. However, given its early stage, I would approach this large platform with your primary use cases, and do a proof of concept first before approaching any production workloads.
However my main complaint is this service should never been called Sagemaker Unified Studio to begin with. Historically Sagemaker has been associated with the AI aspect of AWS, so it is easy to be confused that the new portfolio now includes data engineering. If I had to do it all over I would have called it
AWS Data Unified Studio which has:
Data Engineering Workflows
Sagemaker AI Workflows
Catalog Workflows
Open Table Format Wars
Industry has been talking about the Open Table Format (OTF) wars for a while, and really the problem has been more of a political problem rather than a technological one.
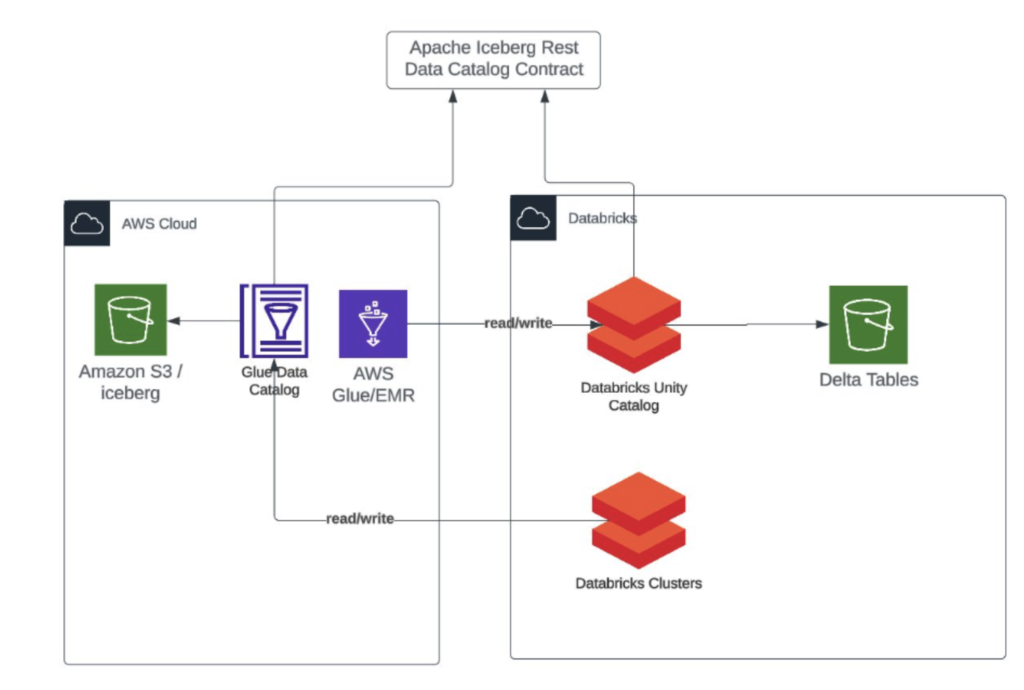
As a reminder, there are 3 major players in the space, Apache Hudi, Apache Iceberg, and Databricks Deltalake. In the past months, AWS, Databricks, and Snowflake have begun to coalesce around allowing catalogs based off Apache Iceberg to query and write to each other.
At its core, Apache Iceberg is a set of specifications. In this case, both the AWS Glue Data Catalog and Databricks have implemented the Apache Iceberg REST contracts, enabling them to query each other. AWS facilitates this by exposing an external endpoint that other vendors can access.
This marks a significant shift in how we approach cross-platform and multi-cloud data querying. What’s puzzling is why there now seems to be broad industry alignment on this paradigm—but regardless, it’s a promising step forward for data engineering. Looking ahead, I wonder if we’ll eventually see true separation of compute and storage across clouds.
This use case is particularly relevant for large enterprises operating across multiple clouds and platforms. For smaller companies, however, it may not be as critical.
What about Apache Hudi for cross query federation? It remains a significant platform, but I’m pessimistic about Apache XTable catching on. However, if your use case involves federated querying across a broader ecosystem, consider this design pattern.
Keep in mind that cross-platform read and write capabilities are being rolled out gradually. Be sure to conduct extensive proof-of-concept (POC) testing to ensure everything functions as expected.
Guidelines through data engineering technology selection
History is often a useful guide, and some are saying the Iceberg format will replace parquet files. As an example, a nifty feature is hidden partitioning, where you can change your partition and not have to rewrite your physical files in storage. The tradeoff is that Iceberg is not the simplest of platforms, you still do need to manage metadata and snapshots.
Here are some tips to guide your projects through a technology selection.
Does you actually have big data?
Big data is a hard term to define but typically think about organizations which have terabytes or petabytes of data. If they do qualify for this, you most likely will choose one of the 3 OTFs.
What ecosystem are you working in? A fair amount of consideration should be given to the ecosystem and technologies they are working in.
What programming languages does your staff know?
Do they have any experience with any previous OTFs
What are the dimensions you need to balance?
There is a weird blending of datalakes and data warehouses now where the lines aren’t clear because features exist in both. We aren’t going to get clear lines soon, so consider these items.
Cost At Scale
After factoring in your projects expected growth patterns, which solution will scale the best at cost? For example, holding petabytes of data is probably better in a datalake than a data warehouse.
Managed or Unmanaged AWS Service?
It’s important to recognize that managed services, such as AWS Glue or MWAA, are not a one-size-fits-all solution. While they simplify operations, they also abstract away fine-tuning capabilities. Managed services often come at a higher cost but reduce operational complexity. When evaluating them, consider both infrastructure costs and the time and effort required for ongoing management.
If your team has the engineering resources and expertise to manage an unmanaged platform, it may be a cost-effective choice at scale. If your project consists of a small team with limited bandwidth, opting for a managed AWS service can help streamline operations and reduce overhead.
Some members of the Hudi team argue that Open Table Formats aren’t truly “open.” While they raise a valid point, vendor lock-in hasn’t been a major concern for most projects. After all, choosing AWS or Databricks also involves a level of vendor lock-in. As a result, the arguments around openness may resonate more with a niche audience rather than the broader industry.
Build Write-Audit-Publish pattern with Apache Iceberg branching and AWS Glue Data Quality
This is a really intriguing pattern for data quality. It enables you to test your data in a staging area, then commit it. This pattern is not necessarily new, but Iceberg’s branching features offers an easier way of doing this
One of the most significant announcements in the data space was Amazon S3 Tables. A common challenge with data lakes is that querying data in S3 can be slow. To mitigate this, techniques like compaction and partitioning are used to reduce the amount of data scanned.
Amazon S3 Tables address this issue by allowing files to be stored in S3 using the native Apache Iceberg format, enabling significantly faster query performance.
However, there is a fair amount of criticism from competitors that there is a substantial mark-up in cost in this service, so be sure to read the S3 table pricing page
Redshift History Mode – Redshift has released a new feature where if you have a zero ETL integration enabled, you can turn on Slowly Changing Dimensions (SCD) Type 2 out of the box.
Our historical pattern used to be
DMS –> S3 (SCD Type 2) –> Spark job to reconcile SCD Type 1 or 2
Now we can do
Zero ETL Redshift Replication –> Access SCD Type 2 tables
This is a relatively new feature so please do your comprehensive testing.
Apache Hudi recently has reached a major milestone of having a 1.0.0 release in December, with several new features
A notable new feature allows users to create indexes on columns other than the Hudi record key, enabling faster lookups on non-record key columns within the table.
There are now 16 new connectors Adobe Analytics, Asana, Datadog, Facebook Page Insights, Freshdesk, Freshsales, Google Search Console, Linkedin, Mixpanel, Paypal Checkout, Quickbooks, SendGrid, SmartSheets, Twilio, WooCommerce and Zoom Meetings for Glue
Here is this quarter’s state of data engineering newsletter. There is only a little chat about AI this time, and a focus on Open Table Formats, the Apache Iceberg Rest Spec, Open Table Format updates, and new updates in the Amazon Data Engineering ecosystem.
Prompt Engineering – Meta Analysis Whitepaper
One of my favorite AI podcasts, Latent Space, recently featured Sander Schulhoff, one of the authors of a comprehensive research paper on prompt engineering. This meta-study reviews over 1,600 published papers, with co-authors from OpenAI, Microsoft, and Stanford.
The whitepaper is an interesting academic deep dive into prompting, and how to increase the quality of it through exemplars (examples provided into an LLM), but not providing too many (more than 20 hurts quality), and strange things like Minecraft agents are tools to understand how this ecosystem works.
Other practical tips are given where asking for data in JSON and XML generally is more accurate and results formatted based of the LLM’s training data is better. That does kind of lead to a problem if you don’t know what the training data is based off
It provides a wide range of tools outside of the two common ones we use the most – chain of thought – which is a multi turn conversation, and retrieval augmented generation (RAG).
We can expect in the next couple of years where LLMs themselves will integrate these workflows so we don’t care about it anymore, but if you want to squeak out some better performance this paper is worth reading.
Open Table Format Wars – Continued
As a quick refresher, the history of data engineering kind of goes like this in 30 seconds
1980s – big data warehouses exist. SQL is lingua franca
2000s – Apache Hadoop ecosystem comes out to address limitations of data warehouses to cope with size and processing
2010s – Datalakes emerge where data is still in cloud storage (E.G. Amazon S3)
2020ish – Datalakehouses or Transactional Datalakes come out to address limitations of Datalakes capability to be ACID compliant
2023 – Consensus emerges over the term Open Table Format (OTF) with three contenders
Apache Hudi
Databrick Deltalake
Apache Iceberg
Mid 2024s
June 3, 2024 – Snowflake announces Polaris catalog support for Apache Iceberg
June 4, 2024 – Databricks buys Tabular (thereby bringing in the founders of Apache Iceberg)
Historically, we see a major shift in technology about every 20 years, with older systems being overhauled to meet new paradigms. Consider the companies that fully embraced Apache Hadoop in the 2000s—they’re now in the process of rebuilding their systems. Right now we are in the middle of the maturing of open table formats.
Data has always kind challenging to deal with because the nature of data is messy, and moving data from one system to another seems simple, but is quite a bit of work as we know most ETL rarely is straight forward when taking into accounts SLAs, schema changes, data volumes, etc.
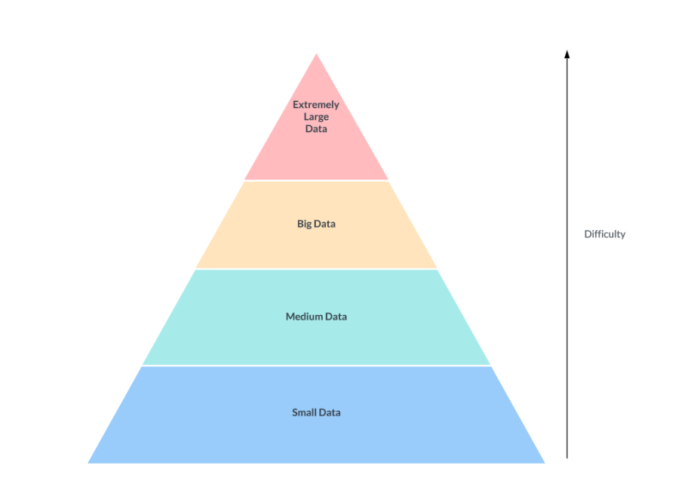
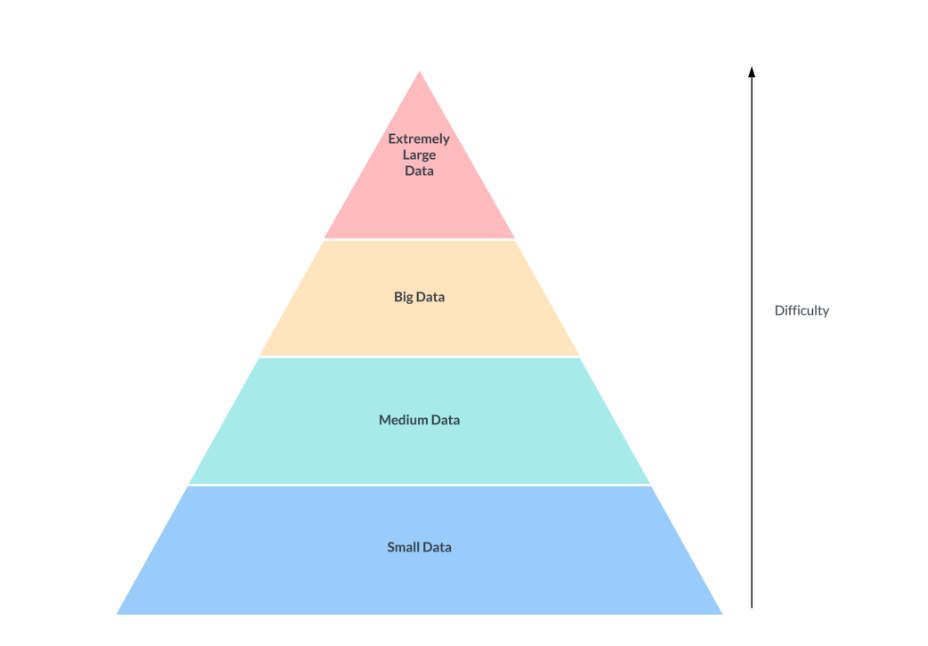
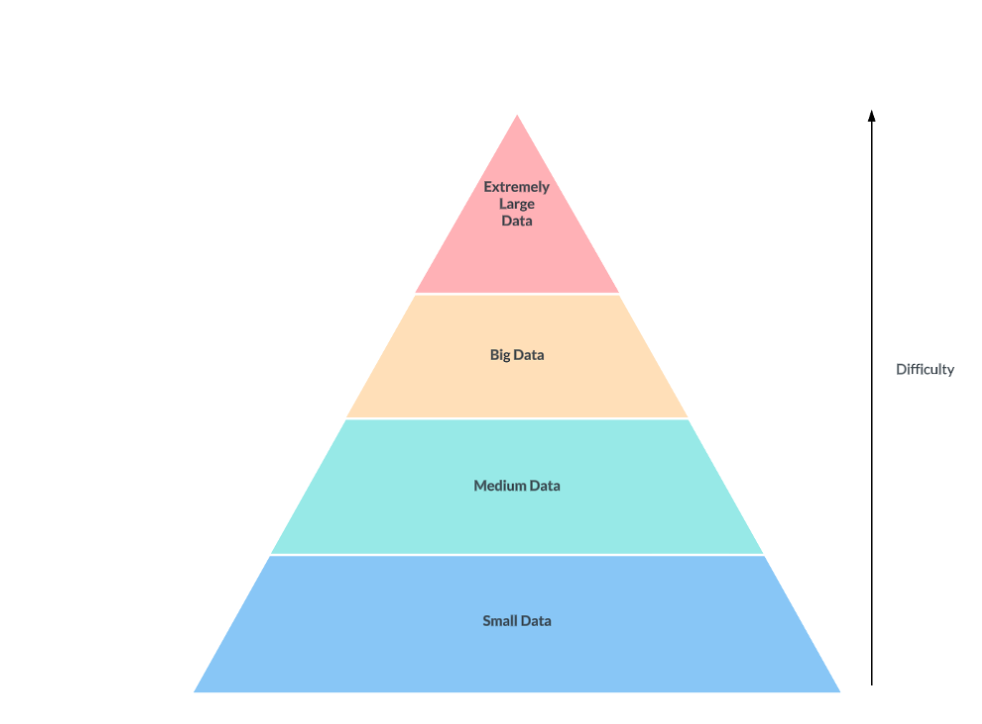
OTFs really matter for us when we deal with big data, and especially for extremely large data (think Uber or Netflix size data). Databases usually can handle the blue and green without problem, but break at the yellow and red.
When working with your data platform, these are key questions you should be asking to help in refining your technology stack.
How much data is being processed (are we talking hundreds of gigabytes, terabytes, or petabytes?)
What is the SLA the data needs to be queried?
What is the existing data foot print in your organization (are you using a lot of MySQL, Microsoft, etc)
Does the organization have the capability to own the engineering effort of an OTF platform?
Do any of the customer’s data sources work for ZeroETL (like Salesforce, Aurora MySQL/Postgres, RDS?)
Is the customer already using Databricks, Hudi, Snowflake, Iceberg, Redshift, or Big Query?
The Future: Interoperability via the Apache Iceberg Catalog API
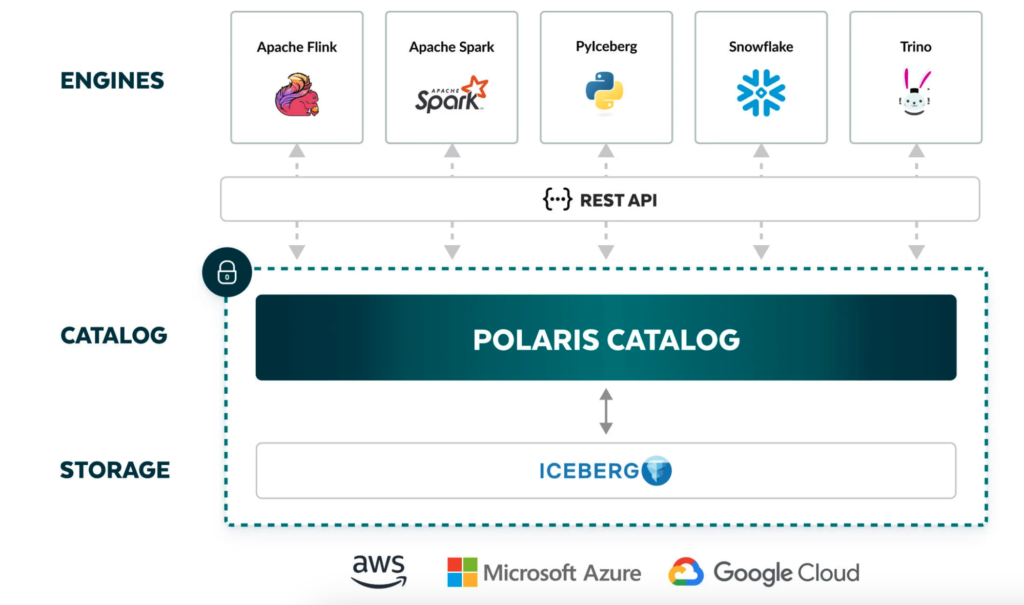
Apache Iceberg, which emerged from Netflix recently has recently been making a lot of news lately. From the acquisition of Tabular (basically the guys who founded Iceberg), to Snowflake open sourcing the Polaris catalog, to Databricks support in private preview, many signs are pointing to a more cross compatible future if certain conditions are met.
There is a pretty important diagram where it shows cross compatibility of AWS, Azure, and Google Cloud. We aren’t here yet, but if all 3 vendors move towards implementing the Apache Iceberg HTTP Catalog API spec, that means cross federated querying will be possible.
I’m hopeful, because ETL’ing data from one place to another place has always been a huge hassle. This type of future really opens up interesting workloads where compute really can be separate even from your cloud.
Everything is a little strange to me, because moving towards the future really isn’t a technology problem, but more of a political one if each cloud choose to move that direction. We are getting signs, but I would say by this time next year, we will learn the intentions of all players. Meanwhile, stay tuned.
New emerging technology: DuckDB
DuckDB was created in 2018 and is a fast in-process analytical database. There is a hosted version called MotherDuck, which is based off a serverless offering. DuckDB takes a different approach where you can run analysis on a large data set either via a CLI or your favorite programming language. The mechanisms are slightly different where the compute runs closer to your application itself.
Article: Running Iceberg and Serverless DuckDB in AWS
In this article, DuckDB can query Iceberg tables stored in S3. Also, as an alternative it describes deploying DuckDB in a serverless environment using ECS with custom containers via HTTP requests.
In the future, I expect AWS to take more notice and integrate DuckDB in the ecosystem in the next couple of years.
Say you have a lot of log data in EC2. Typically, you would load it into S3 and query via Athena. Instead you could load the data in EC2, and then load a DuckDB instance there where you can query it without penalty for exploration
Preprocessing and pre-cleaning of user-generated data for machine learning training
Any type of system that previously used SQLite
Exploration of any data sets if it is on your laptop – this one is a no brainer.
— Iceberg Updates:
[Article]: The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables
Amazon previously tackled the issue of small file accumulation in Apache Iceberg tables by introducing automatic compaction. This feature consolidated small files into larger ones, improving query performance and reducing metadata overhead, ultimately optimizing storage and enhancing analytics workloads.
Building on this, Amazon has now released a new feature in AWS Glue Data Catalog that automatically deletes expired snapshots and removes orphan files. This addition helps control storage costs and maintain compliance with data retention policies by cleaning up unnecessary data, offering a more complete solution for managing Iceberg tables efficiently.
[Feature]: Accelerate query performance with Apache Iceberg statistics on the AWS Glue Data Catalog
TLDR: If you want faster SLA in Iceberg tables, run the table statistics feature for a potential of 24 –> 80% in improvement in query time
Column-level statistics are a method for enhancing the query performance of Iceberg tables in Amazon Redshift Spectrum and Athena. These statistics are based on the Puffin file format and allow query engines to optimize SQL operations more effectively. You can enable this feature via the AWS Console or by running an AWS Glue job. According to the performance data in the blog post, improvements range from 24% to 83%, simply by running a job to store metadata.
Summary:
Use this if you have large datasets and need consistent query performance. Small datasets may not benefit enough to justify the effort.
Be aware of the overhead involved in running and maintaining statistics jobs.
Since data will likely change over time, you should set up automated jobs to periodically regenerate the statistics to maintain performance gains. While manual effort is required now, this feature could be more integrated into the platform in the future.
[Article]: Petabyte-Scale Row-Level Operations in Data Lakehouses Authors: Apache Foundation, Apple Employees, Founder of Apache Iceberg
We rarely have run into the scale of needed to run petabyte row level changes, but it details a strategy with these techniques
Technique
Explanation
Hudi Equivalent
Databricks Equivalent
Eager Materialization
Rewrites entire data files when rows are modified; suitable for bulk updates.
Copy-on-Write (COW)
Data File Replacement
Lazy Materialization
Captures changes in delete files, applying them at read time; more efficient for sparse updates.
Merge-on-Read (MOR)
Delete Vectors
Position Deletes
Tracks rows for deletion based on their position within data files.
Delete Vectors
Equality Deletes
Deletes rows based on specific column values, e.g., row ID or timestamp.
Delete Vectors
Storage-Partitioned Joins
Eliminates shuffle costs by ensuring data is pre-partitioned based on join keys.
Low Shuffle MERGE
Runtime Filtering
Dynamically filters out unnecessary data during query execution to improve performance.
Runtime Optimized Filtering
Executor Cache
Caches delete files in Spark executors to avoid redundant reads and improve performance.
Adaptive Writes
Dynamically adjusts file sizes and data distribution at runtime to optimize storage and prevent skew.
Minor Compaction
Merges delete files without rewriting the base data to maintain read performance.
Compaction in MOR
Hybrid Materialization
Combines both eager and lazy materialization strategies to optimize different types of updates.
The paper also half reads as a marketing paper for Iceberg, but the interesting aspect is that half of the authors are from Apple. One of the authors of that paper also made this video on how Apache Iceberg is used at Apple.
This article essentially serves as marketing for Amazon EMR, but it also demonstrates the product team’s commitment to enhancing performance with Apache Iceberg. It’s a slightly curious comparison, as most users on AWS would likely already be using EMR rather than managing open-source Spark on EC2. Nevertheless, the article emphasizes that EMR’s custom Spark runtime optimizations are significantly faster than running open-source Spark (OSS) on EC2.
Optimizations for DataSource V2 (dynamic filtering, partial hash aggregates).
Better query planning and optimized physical operators for faster execution.
Integration with Amazon S3 for reduced I/O and data scanning.
Java runtime improvements for better memory and garbage collection management.
Optimized joins and aggregations, reducing shuffle and join overhead.
Increased parallelism and efficient task scheduling for better cluster utilization.
Improved resource management and autoscaling for cost and performance optimization.
[Article]: Using Amazon Data Firehose to populate Iceberg Tables TLDR: Use this technique if you might need Iceberg tables from the raw zone for streaming data and you need ACID guarantees
Recently, a sharp-eyed developer spotted an exciting new feature in a GitHub Changelog: Amazon Data Firehose now has the ability to write directly to Iceberg tables. This feature could be hugely beneficialfor anyone working with streaming data and needing ACID guarantees in their data lake architecture.
Warning: This feature isn’t production-ready yet, but it’s promising enough that we should dive into how it works and how it simplifies the data pipeline.
: An Interesting Future: Example of Iceberg being queried from Snowflake and Databricks
Randy Pitcher from Databricks shows an example how an Iceberg table created in Databricks is queried with Snowflake. As mentioned earlier, the chattering is not all vendors are fully implemented the Catalog API spec (yet), but once this gets mature in 2026-ish, expect the ability to query data across cloud to be possible.
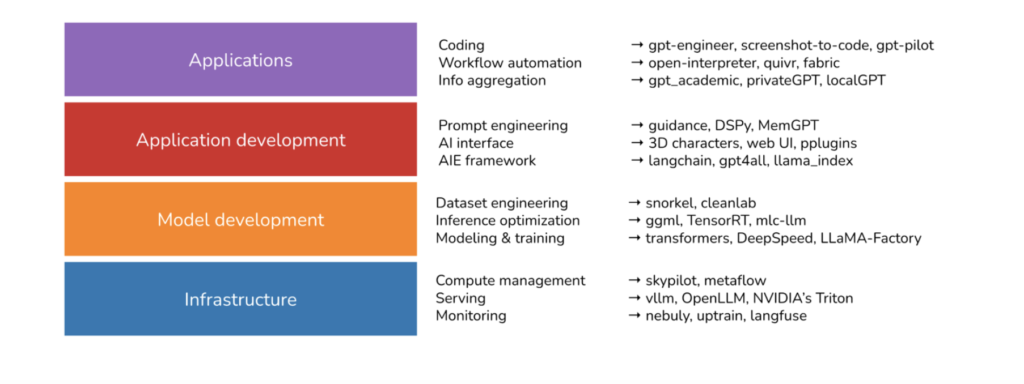
Chip Huyen, who came out of Stanford and is active in the AI space recently wrote an article on what she learned by looking at the 900 most popular open source AI tools.
In data engineering, one of our primary usages of AI is really just prompt engineering.
Use Case 1: Data Migration
Before LLMs, when we did data migrations, we would use Amazon Schema Conversion Tool (SCT) first to help convert source schemas to a new target schema. Let us say we are going from SQLServer to Postgres, which is a major language change.
From there, the hard part begins where you need to manually convert the SQL Server SQL business logic code to Postgres. Some converters do exist out there, and I assume they work on a basis of mapping a language grammar from one to another (fun fact – I almost pursued a PhD in compiler optimization, but bailed from the program).
Now what we can do is use LLMs to convert a huge set of code from one source to a target using prompt engineering. Despite a lot of the new open source models out there, Chat GPT 4 still seems to be outperforming the competitors for the time being in doing this type of code conversions.
The crazy thing is with the LLMs, we can convert really one source system to any source system. If you try it out Java to C#, SQL to Spark SQL, all work somewhat reasonably well. In terms of predictions of our field I see a couple things progressing
Phase 1 Now:
Productivity gains of code conversions using LLMs
Productivity gains of coding itself of tools like Amazon Code Whisperer or Amazon Q or LLM of your choice for faster coding
Productivity gains of learning a new language with LLMS
Debugging stack traces by having LLMs analyze it
Phase 2: Near Future
Tweaks of LLMs to make them more deterministic for prompt engineering. We already have the ability to control creativity with the ‘temperature’ parameter, but we generally have to give really tight prompt conditions to get some of the code conversions to work. In some of our experimentations with SQL to SparkSQL, doing things like passing in the DDLs have forced the LLMs to generate more accurate information.
An interesting paper about using chain of thought with prompting (a series of intermediate reasoning steps), might help us move towards this Arxiv paper here – https://arxiv.org/abs/2201.11903
In latent.space’s latest newsletter, they mentioned a citation of a paper adding “Let’s think step by step” improved zero shot reasoning from 17 to 79%. If you happen to DM me and say that in an introduction I will raise an eyebrow. latent.space citation link
Being able to use LLMs to create data quality tests based on schemas or create unit tests based off existing ETL code.
Phase 3: Future
The far scary future is where we tell LLMs how to create our data engineering systems. Imagine telling it to ingest data from S3 into an Open Table Format (OTF) and to write business code on top of this. I kind of don’t see this for at least 10ish years though.
Open Table Format Wars – Continued
The OTF wars continue to rage with no end in site. As a refresher, there are 3 players
Apache Hudi – which came out of the Uber project
Apache Iceberg – which came out of the Netflix project
Databricks Deltalake.
As a reminder, OTFs provide features some as time travel features, incremental ETL, deletion capability, and schema evolution-ish capability depending on which one you use.
Perhaps one of the biggest subtle changes which has recently happened is that the OneTable project is now Apache X Table.
Apache X Table is a framework to seamlessly do cross-table work between any of the OTFs. I still think this is ahead of its time because I haven’t seen any project that have needs to combine multiple OTFs in an organization. My prediction though is in 5-10 years this format will become a standard to allow vendor interoperability, but it will take a while.
Apache Hudi Updates
Newsletter – https://hudinewsletter.substack.com/ – because we all can’t get enough Substack in our lives, Hudi now has a newsletter you can check for updates
Lake Formation, which still is a bit weird to me as one part of it is blue prints which we really don’t use, and the other part which deals with access control, rolled out some new changes with OTF integration and ACL
It is still kind of mess, and there still really aren’t any clear winners. There are also multiple options where you can choose to go the open source branch or with a hosted provide with One House or Tabular.
The false promises of AWS announcements – S3 Express Zones
Around Re:invent, there are always a huge set of announcements, and one stood out, S3 Express Zones. This feature would allow retrieval of data in S3 in the single digit milliseconds with the tradeoffs of storage being in one zone (so no HA). You can imagine if this actually works, datalakes can hypothetically start competing with databases as we wouldn’t need to worry about the SLA time penalty you usually get with S3.
Looking at the restrictions there are some pretty significant drawbacks.
As you can see here Hudi isn’t supported (not sure why Iceberg tables aren’t there), and Deltalake has partial support. The other consideration is this is in one zone, so you have to make sure there is a replicated bucket in a standard zone.
I kind of feel that Amazon seems to test the waters by launching not fully formed products, to get feedback from us. Unfortunately that makes us the guinea pigs
TLDR – This service works for Glue jobs, but for OTFs, it is dead in the water for the time being.
Amazon Q
I remember being in an AWS roundtable representing data consulting companies at Re:invent and a complaint from other firms was that Amazon had too many confusing products. As we are all guinea pigs in their early services, Amazon Q is no exception.
Use Case
Features
Amazon Q for Business
Chatbot for internal enterprise data that is managed by Amazon. No dev work required
Chatbot
Amazon Q For Developers
Best for doing basic coding and coding with AWS specific services.
Broader coding is probably better with a foundational model
Code completion – Code whisperer
Chat – Amazon Q
TLDR
Amazon Q for business is a managed product where you click and add data sources and a chatbot is used
Amazon Q for developers contains Code completion (Code Whisperer) AND a chat in Visual Studio IDE with, yes, Amazon Q again as the chat. Confused yet?
Quicksight Q
I’d like to confuse you one more time with the history of Quicksight Q. Pre ChatGPT and LLM craze, Quicksight Q in 2021 went Generally Available (GA) being powered by Machine Learning
After Chat GPT came out, Quicksight Q went back into Preview
With LLM integration, but they kept the same name.
One of the things to really keep in mind is as you do your solutions architecture, you need to keep in mind of a service is in preview or GA. Things in preview typically only support a couple regions and don’t have production support. If you are interested in a service in preview (like Amazon Q), it is advisable to wait a bit.
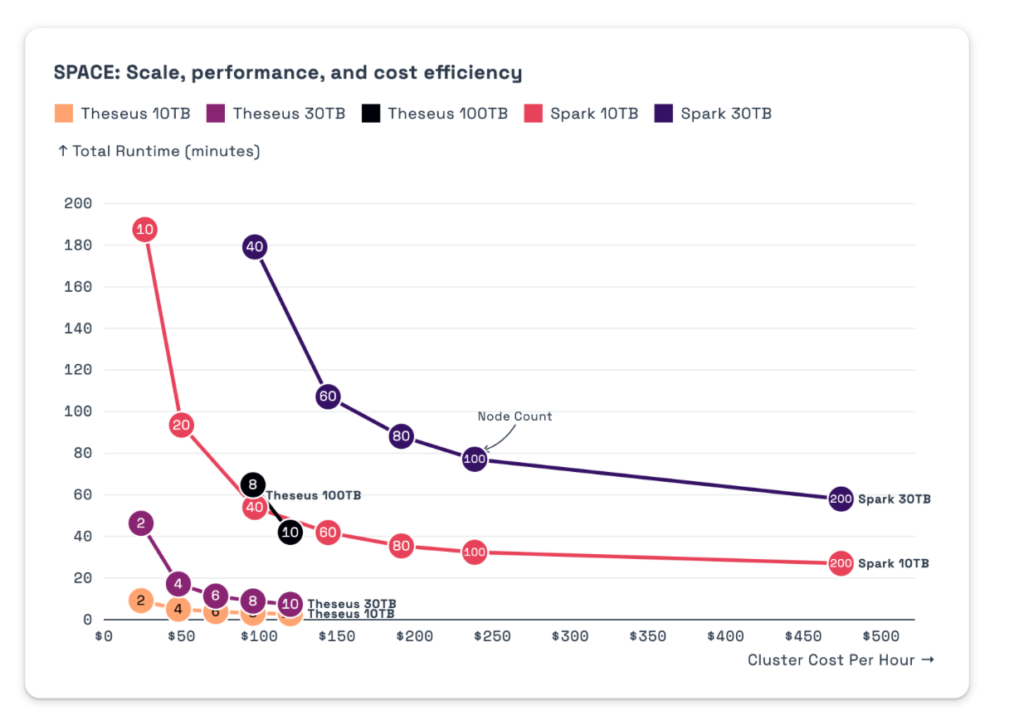
A Framework for Processing Uber Uber Large Sets of Data – Theseus
I show this diagram very often, and as a refresher, a lot of the work we do in data engineering is yellow and in red, and often involves OTFS.
Voltron Data, who created a GPU Query Engine called Theseus, put out these benchmarks comparing their framework Theseus vs Spark
Image Credit: Voltran’s Blog1 Their guidance also quite interesting
For less than 2TBs: We believe DuckDB and Arrow backed projects, DataFusion, and Polars make a lot of sense. This is probably the majority of datasets in the world and can be run most efficiently leveraging these state-of-the-art query systems.
For up to 30TBs: Well-known data warehouses like Snowflake, Google BigQuery, Databricks, and distributed processing frameworks like Spark and Trino work wonders at this scale.
For anything over 30TBs: This is where Theseus makes sense. Our minimum threshold to move forward requires 10TB queries (not datasets), but we prefer to operate when queries exceed 100TBs. This is an incredibly rare class of problem, but if you are feeling it, you know how quickly costs balloon, SLAs are missed, and tenuously the data pipeline is held together.
I mostly work in the AWS space, but it is interesting to peek on what innovations are going on outside of the space.
The author of Apache Arrow also made this observation
</= 1TB — DuckDB, Snowflake, DataFusion, Athena, Trino, Presto, etc.
You might ask, what my guidance might be for the Amazon space?
< 100 gigabytes – your run of the mill RDS or Aurora
>= 100 gigabytes – 30 TB – Redshift, or OTF
>30 TB – We haven’t really played in this space but things like Apache Iceberg are probably better candidates
TLDR – you probably will never use Theseus, so this is just a fun article.
American Privacy Rights Act (APRA)
There was a bit of surprising news coming out of the US Congress that there is now draft legislation for a national data privacy rights for Americans. In the United States, data privacy has consisted of an odd patchwork of legislation state to state (like CCPA in California or the Colorado Privacy Act). The US really is quite behind in legislation as the rest of the world has some type of privacy legislation.
Deletion Requests: Companies are required to delete personal data upon an individual’s request and must notify any third parties who have received this data to do the same.
Third-Party Notifications: Companies must inform third parties of any deletion requests, ensuring that these third parties also delete the relevant data.
Verification of Requests: Companies need to verify the identity of individuals who request data deletion or correction to ensure the legitimacy of these requests.
Exceptions to Deletion: There are specific conditions under which a company may refuse a deletion request, such as legal restrictions, implications for data security, or if it would affect the rights of others.
Technological and Cost Constraints: If it is technologically impossible or prohibitively expensive to comply with a deletion request, companies may decline the request but must provide a detailed explanation to the individual.
Frequency and Cost of Requests: Companies can allow individuals to exercise their deletion rights free of charge up to three times per year; additional requests may incur a reasonable fee.
Timely Response: Companies must respond to deletion requests within specified time frames, generally within 15 to 30 days, depending on whether they qualify as large data holders or not.
Who is this applicable for?
Large Data Holders: The Act defines a “large data holder” as a covered entity that, in the most recent calendar year, had annual gross revenue of not less than $250 million and, depending on the context, meets certain thresholds related to the volume of covered data processed. These thresholds include handling the covered data of more than 5 million individuals, 15 million portable connected devices identifying individuals, or 35 million connected devices that can be linked to individuals. Additionally, for handling sensitive covered data, the thresholds are more than 200,000 individuals, 300,000 portable connected devices, or 700,000 connected devices.
Small Business Exemptions: The Act specifies exemptions for small businesses. A small business is defined based on its average annual gross revenues over the past three years not exceeding $40 million and not collecting, processing, retaining, or transferring the covered data of more than 200,000 individuals annually for purposes other than payment collection. Furthermore, all covered data for such purposes must be deleted or de-identified within 90 days unless retention is necessary for fraud investigations or consistent with a return or warranty policy. A small business also must not transfer covered data to a third party in exchange for revenue or other considerations.
A while back I worked on a data engineering project which was exposed to the European GDPR. It was interesting because we had meetings with in-house counsel lawyers to discuss what kind of data policies they had in place. One of the facets of GDPR which is similar here is the ‘right to remove data.’
We entered some gray areas as when talking with lawyers the debate was occurring which data would be removed? Removing data from a database or data lake is clear if it contained customer data, but what if it was deeply nestled in Amazon Glacier?
I don’t really have any great answers, but if this legislation actually does pan out, it makes a strong case for large companies to use OTFs for their data lakes otherwise it would be extremely difficult to delete the data.
TLDR – if you are a solution architect, do ask what kind of data policy exposure they have. If this legislation does pass, please pay attention when you start your projects based in the USA whether this legislation is applicable to them based of the final legislation.
Fortunately uhh I don’t think anyone in our team is named Devon, but this video has been making its rounds the Internet as the first ‘AI software engineer’
The current state of data engineering offers a plethora of options in the market, which can be challenging when selecting the right tool We are approaching a period where the traditional boundaries between between databases, datalakes, and data warehouses are overlapping. As always, it is important to think about what is the business case, then do a technology selection afterwards.
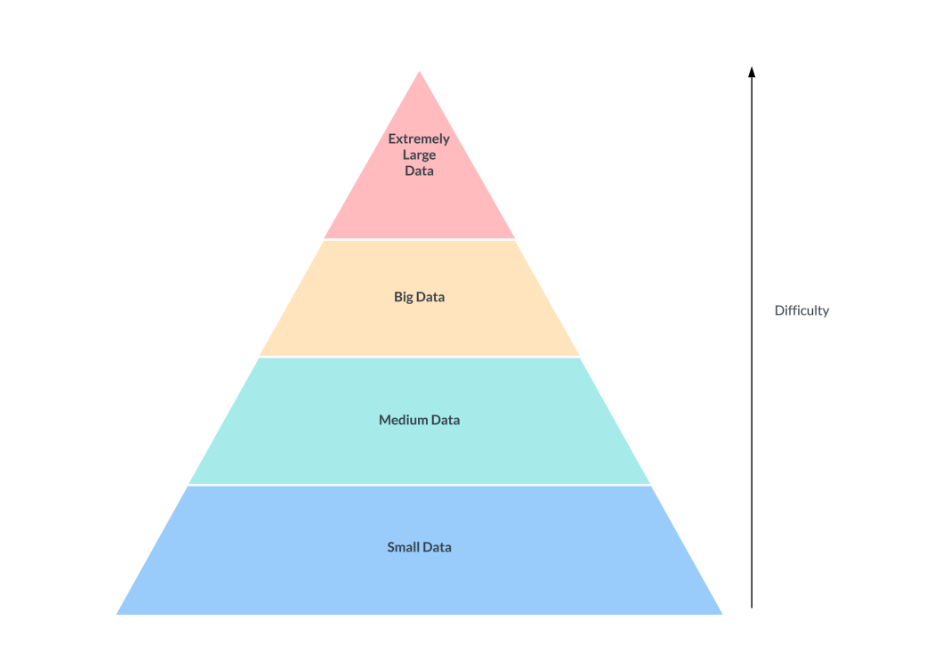
This diagram is simple, but merits some discussion.
Most companies in the small and medium data fields can get away with simpler architectures with a standard database powering their business applications. However it is when you get into big data and extremely large data do you want to start looking at more advanced platforms.
The Open Source Table Format Wars Revisited
A growing agreement is forming around the terminology used for Open Table Formats (OTF), also known as Open Source Table Formats (OSTF). These formats are particularly beneficial in scenarios involving big data or extremely large datasets, similar to those managed by companies like Uber and Netflix. Currently, there are three major contenders in the OTF space.
Every datalake eventually suffers from a small file problem. What this means is if you have too many files in a given S3 partition (aka file path), performance degrades substantially. To alleviate this, compaction jobs are run to merge files to bigger files to improve performance. In managed paid platforms, this is done automatically for you, but in the open source platforms, developers are on the hook in needing to do this.
I was surprised to read that now if you use Apache Iceberg tables, developers no long have to deal with compaction jobs. Now to the second announcement:
Amazon Redshift announces general availability of support for Apache Iceberg
Microsoft, the Hudi team, and the Databricks team got together to create a new standard that serves as an abstraction layer on top of an OTF. This is odd to me, because not too many organizations have these data stacks concurrently deployed.
However probably in the next couple years as abstraction layers get created on top of OTFs, this will be something to watch.
Amazon S3 Express One Zone Storage Class
Probably one of the most important but probably buried news from re:Invent was the announcement of Amazon S3 Express One Zone
With this, we can now have single digit millisecond access to data information to S3, which leads to a weird question of datalakes encroaching onto database territory if they now can meet higher SLAs. However there are some caveats with this as there is limited region availability, and it is in one zone so think about your disaster recovery requirements. This is one feature I would definitely watch.
Zero ETL Trends
Zero ETL is the ability for behind the scenes replication for Aurora, RDS, and Dynamo to replicate to Redshift. If you have a use case where Slowly Changing Dimensions (SCD) Type 1 is acceptable, these are all worth taking a look at. From my understanding, when replication occurs, there is no connection penalty to your Redshift cluster.
It is exciting to see the OTF ecosystem evolve. Apache Hudi is still a great and mature option, with Apache Iceberg now being more integrated with the AWS ecosystem.
Zero ETL has the potential to save your organization a ton of time if your data sources are supported by it.
Something to consider is that major shifts in data engineering occur every couple of months, so keep an eye on new developments, as they can have profound impacts on enterprise data strategies and operations.