Data Engineering and AI
Chip Huyen, who came out of Stanford and is active in the AI space recently wrote an article on what she learned by looking at the 900 most popular open source AI tools.
https://huyenchip.com/2024/03/14/ai-oss.html
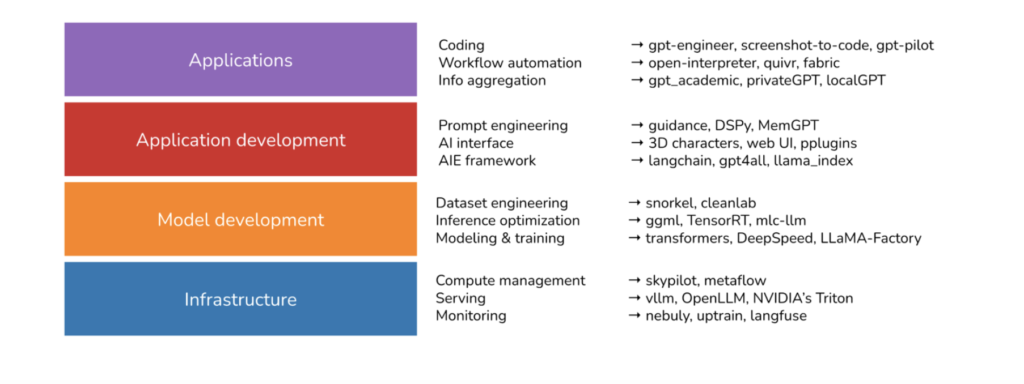
Image Credit: huyenchip’s blog
In data engineering, one of our primary usages of AI is really just prompt engineering.
Use Case 1: Data Migration
Before LLMs, when we did data migrations, we would use Amazon Schema Conversion Tool (SCT) first to help convert source schemas to a new target schema. Let us say we are going from SQLServer to Postgres, which is a major language change.
From there, the hard part begins where you need to manually convert the SQL Server SQL business logic code to Postgres. Some converters do exist out there, and I assume they work on a basis of mapping a language grammar from one to another (fun fact – I almost pursued a PhD in compiler optimization, but bailed from the program).
Now what we can do is use LLMs to convert a huge set of code from one source to a target using prompt engineering. Despite a lot of the new open source models out there, Chat GPT 4 still seems to be outperforming the competitors for the time being in doing this type of code conversions.
The crazy thing is with the LLMs, we can convert really one source system to any source system. If you try it out Java to C#, SQL to Spark SQL, all work somewhat reasonably well. In terms of predictions of our field I see a couple things progressing
Phase 1 Now:
- Productivity gains of code conversions using LLMs
- Productivity gains of coding itself of tools like Amazon Code Whisperer or Amazon Q or LLM of your choice for faster coding
- Productivity gains of learning a new language with LLMS
- Debugging stack traces by having LLMs analyze it
Phase 2: Near Future
- Tweaks of LLMs to make them more deterministic for prompt engineering. We already have the ability to control creativity with the ‘temperature’ parameter, but we generally have to give really tight prompt conditions to get some of the code conversions to work. In some of our experimentations with SQL to SparkSQL, doing things like passing in the DDLs have forced the LLMs to generate more accurate information.
- An interesting paper about using chain of thought with prompting (a series of intermediate reasoning steps), might help us move towards this
Arxiv paper here – https://arxiv.org/abs/2201.11903 - In latent.space’s latest newsletter, they mentioned a citation of a paper adding “Let’s think step by step” improved zero shot reasoning from 17 to 79%. If you happen to DM me and say that in an introduction I will raise an eyebrow.
latent.space citation link
- Being able to use LLMs to create data quality tests based on schemas or create unit tests based off existing ETL code.
Phase 3: Future
- The far scary future is where we tell LLMs how to create our data engineering systems. Imagine telling it to ingest data from S3 into an Open Table Format (OTF) and to write business code on top of this. I kind of don’t see this for at least 10ish years though.
Open Table Format Wars – Continued
The OTF wars continue to rage with no end in site. As a refresher, there are 3 players
- Apache Hudi – which came out of the Uber project
- Apache Iceberg – which came out of the Netflix project
- Databricks Deltalake.
As a reminder, OTFs provide features some as time travel features, incremental ETL, deletion capability, and schema evolution-ish capability depending on which one you use.
Perhaps one of the biggest subtle changes which has recently happened is that the OneTable project is now Apache X Table.
Apache X Table is a framework to seamlessly do cross-table work between any of the OTFs. I still think this is ahead of its time because I haven’t seen any project that have needs to combine multiple OTFs in an organization. My prediction though is in 5-10 years this format will become a standard to allow vendor interoperability, but it will take a while.
Apache Hudi Updates
- Newsletter – https://hudinewsletter.substack.com/ – because we all can’t get enough Substack in our lives, Hudi now has a newsletter you can check for updates
- For those who want a high level overview of Hudi, this blog is a nice quick read https://defogdata.substack.com/p/table-format-series-apache-hudi-hadoop
- Our favorite data influencer Soumil Shah has an article about the Apache X Table (which I don’t think it is relevant for now, but still is an interesting read) – https://www.linkedin.com/pulse/advanced-data-management-building-multi-modal-indexing-soumil-shah-ux95f/
Apache Iceberg Updates
- Views are now available! – https://github.com/apache/iceberg/releases/tag/apache-iceberg-1.5.0
- AWS Blog on how to do schema evolution – https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/
- Tabular article on mirror CDC https://tabular.io/blog/mirroring-data-cdc-in-apache-iceberg-with-debezium-and-kafka-connect/
- Still no consensus what to call these OTFs, lake house, or transaction datalakes, I dunno, but here is an article pro Iceberg – https://hightouch.com/blog/iceberg-rise-of-the-lakehouse
Lake Formation
Lake Formation, which still is a bit weird to me as one part of it is blue prints which we really don’t use, and the other part which deals with access control, rolled out some new changes with OTF integration and ACL
- OTF Lake Formation Integration – https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
Summary about state of the OTF Market
It is still kind of mess, and there still really aren’t any clear winners. There are also multiple options where you can choose to go the open source branch or with a hosted provide with One House or Tabular.
The false promises of AWS announcements – S3 Express Zones
Around Re:invent, there are always a huge set of announcements, and one stood out, S3 Express Zones. This feature would allow retrieval of data in S3 in the single digit milliseconds with the tradeoffs of storage being in one zone (so no HA). You can imagine if this actually works, datalakes can hypothetically start competing with databases as we wouldn’t need to worry about the SLA time penalty you usually get with S3.
Looking at the restrictions there are some pretty significant drawbacks.
https://docs.aws.amazon.com/athena/latest/ug/querying-express-one-zone.html

As you can see here Hudi isn’t supported (not sure why Iceberg tables aren’t there), and Deltalake has partial support. The other consideration is this is in one zone, so you have to make sure there is a replicated bucket in a standard zone.
I kind of feel that Amazon seems to test the waters by launching not fully formed products, to get feedback from us. Unfortunately that makes us the guinea pigs
TLDR – This service works for Glue jobs, but for OTFs, it is dead in the water for the time being.
Amazon Q
I remember being in an AWS roundtable representing data consulting companies at Re:invent and a complaint from other firms was that Amazon had too many confusing products. As we are all guinea pigs in their early services, Amazon Q is no exception.
| Use Case | Features | |
| Amazon Q for Business | Chatbot for internal enterprise data that is managed by Amazon. No dev work required | Chatbot |
| Amazon Q For Developers | Best for doing basic coding and coding with AWS specific services. Broader coding is probably better with a foundational model | Code completion – Code whisperer Chat – Amazon Q |
TLDR
- Amazon Q for business is a managed product where you click and add data sources and a chatbot is used
- Amazon Q for developers contains Code completion (Code Whisperer) AND a chat in Visual Studio IDE with, yes, Amazon Q again as the chat. Confused yet?
Quicksight Q
I’d like to confuse you one more time with the history of Quicksight Q. Pre ChatGPT and LLM craze, Quicksight Q in 2021 went Generally Available (GA) being powered by Machine Learning
https://aws.amazon.com/about-aws/whats-new/2021/09/amazon-quicksight-q-generally-available
After Chat GPT came out, Quicksight Q went back into Preview

With LLM integration, but they kept the same name.
One of the things to really keep in mind is as you do your solutions architecture, you need to keep in mind of a service is in preview or GA. Things in preview typically only support a couple regions and don’t have production support. If you are interested in a service in preview (like Amazon Q), it is advisable to wait a bit.
A Framework for Processing Uber Uber Large Sets of Data – Theseus
I show this diagram very often, and as a refresher, a lot of the work we do in data engineering is yellow and in red, and often involves OTFS.
Voltron Data, who created a GPU Query Engine called Theseus, put out these benchmarks comparing their framework Theseus vs Spark
https://voltrondata.com/benchmarks/theseus
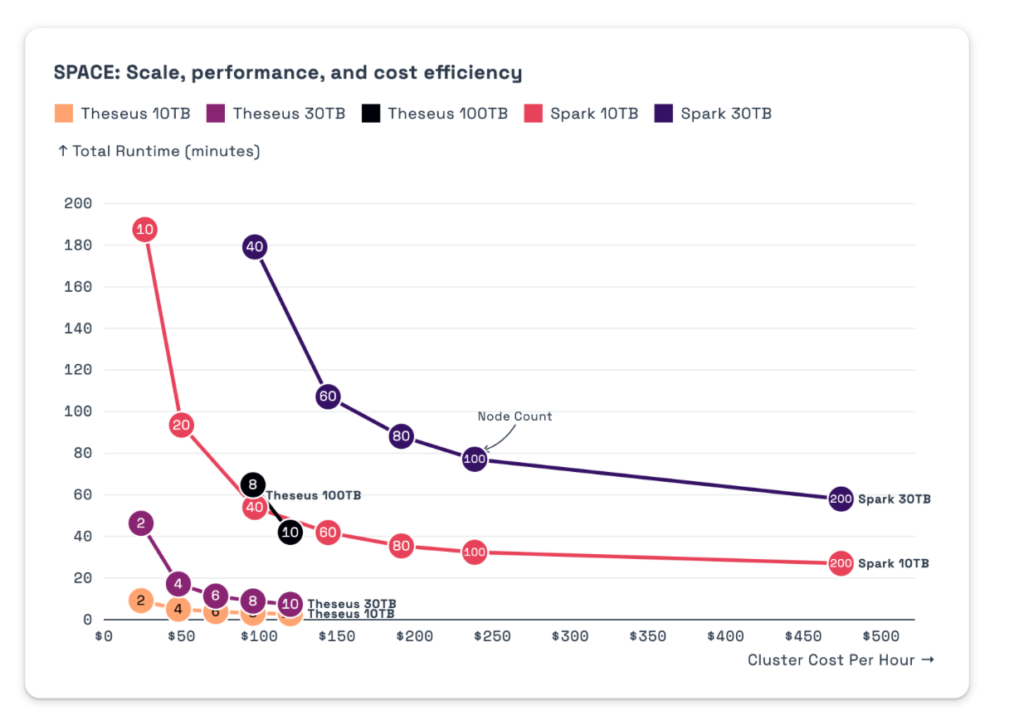
Image Credit: Voltran’s Blog1
Their guidance also quite interesting
For less than 2TBs: We believe DuckDB and Arrow backed projects, DataFusion, and Polars make a lot of sense. This is probably the majority of datasets in the world and can be run most efficiently leveraging these state-of-the-art query systems.
For up to 30TBs: Well-known data warehouses like Snowflake, Google BigQuery, Databricks, and distributed processing frameworks like Spark and Trino work wonders at this scale.
For anything over 30TBs: This is where Theseus makes sense. Our minimum threshold to move forward requires 10TB queries (not datasets), but we prefer to operate when queries exceed 100TBs. This is an incredibly rare class of problem, but if you are feeling it, you know how quickly costs balloon, SLAs are missed, and tenuously the data pipeline is held together.
I mostly work in the AWS space, but it is interesting to peek on what innovations are going on outside of the space.
The author of Apache Arrow also made this observation
- </= 1TB — DuckDB, Snowflake, DataFusion, Athena, Trino, Presto, etc.
- 1–10TB — Spark, Dask, Ray, etc.
- 10TB — hardware-accelerated processing (e.g., Theseus).
(citation credit link)
You might ask, what my guidance might be for the Amazon space?
- < 100 gigabytes – your run of the mill RDS or Aurora
- >= 100 gigabytes – 30 TB – Redshift, or OTF
- >30 TB – We haven’t really played in this space but things like Apache Iceberg are probably better candidates
TLDR – you probably will never use Theseus, so this is just a fun article.
American Privacy Rights Act (APRA)
There was a bit of surprising news coming out of the US Congress that there is now draft legislation for a national data privacy rights for Americans. In the United States, data privacy has consisted of an odd patchwork of legislation state to state (like CCPA in California or the Colorado Privacy Act). The US really is quite behind in legislation as the rest of the world has some type of privacy legislation.
Here are some draft highlights
- Deletion Requests: Companies are required to delete personal data upon an individual’s request and must notify any third parties who have received this data to do the same.
- Third-Party Notifications: Companies must inform third parties of any deletion requests, ensuring that these third parties also delete the relevant data.
- Verification of Requests: Companies need to verify the identity of individuals who request data deletion or correction to ensure the legitimacy of these requests.
- Exceptions to Deletion: There are specific conditions under which a company may refuse a deletion request, such as legal restrictions, implications for data security, or if it would affect the rights of others.
- Technological and Cost Constraints: If it is technologically impossible or prohibitively expensive to comply with a deletion request, companies may decline the request but must provide a detailed explanation to the individual.
- Frequency and Cost of Requests: Companies can allow individuals to exercise their deletion rights free of charge up to three times per year; additional requests may incur a reasonable fee.
- Timely Response: Companies must respond to deletion requests within specified time frames, generally within 15 to 30 days, depending on whether they qualify as large data holders or not.
Who is this applicable for?
- Large Data Holders: The Act defines a “large data holder” as a covered entity that, in the most recent calendar year, had annual gross revenue of not less than $250 million and, depending on the context, meets certain thresholds related to the volume of covered data processed. These thresholds include handling the covered data of more than 5 million individuals, 15 million portable connected devices identifying individuals, or 35 million connected devices that can be linked to individuals. Additionally, for handling sensitive covered data, the thresholds are more than 200,000 individuals, 300,000 portable connected devices, or 700,000 connected devices.
- Small Business Exemptions: The Act specifies exemptions for small businesses. A small business is defined based on its average annual gross revenues over the past three years not exceeding $40 million and not collecting, processing, retaining, or transferring the covered data of more than 200,000 individuals annually for purposes other than payment collection. Furthermore, all covered data for such purposes must be deleted or de-identified within 90 days unless retention is necessary for fraud investigations or consistent with a return or warranty policy. A small business also must not transfer covered data to a third party in exchange for revenue or other considerations.
A while back I worked on a data engineering project which was exposed to the European GDPR. It was interesting because we had meetings with in-house counsel lawyers to discuss what kind of data policies they had in place. One of the facets of GDPR which is similar here is the ‘right to remove data.’
We entered some gray areas as when talking with lawyers the debate was occurring which data would be removed? Removing data from a database or data lake is clear if it contained customer data, but what if it was deeply nestled in Amazon Glacier?
I don’t really have any great answers, but if this legislation actually does pan out, it makes a strong case for large companies to use OTFs for their data lakes otherwise it would be extremely difficult to delete the data.
TLDR – if you are a solution architect, do ask what kind of data policy exposure they have. If this legislation does pass, please pay attention when you start your projects based in the USA whether this legislation is applicable to them based of the final legislation.
Citation Link and Credit For Talking About This – Hard Fork Podcast
Everything Else
Glue: Observability
The AWS Team recently put out a blog series on monitoring and debugging AWS Jobs using observability metrics.
DBT
- The DBT team also released their 2024 state of analytics engineering (PDF here) –
- TLDR, data quality is still of big concern
- I’m surprised data mesh is still a thing, although it seems like it is only for big orgs according to the survey
AWS Exams:
AWS released a free training course on the Data Engineer Associate Exam
Also note the AWS Specialty Analytics and Database Specialty exams are being retired this month.
YADT (Yet Another Data Tool)
As if there weren’t enough tools on the market..
- Kestra – Airflow competitor – https://github.com/kestra-io/kestra
- Starrocks – An open source data warehouse (Redshift competitor) – https://www.starrocks.io/
- Apache Superset – An alternative to paid BI (like Quicksight ) – https://docs.google.com/presentation/d/1GaIN0p6msfYm3ZzwPoV6q4HqARXi0003AxVyxqDs_jU/edit?ref=blef.fr#slide=id.g2ca5e1ff3e2_0_236
- Puppy graph – Query your data as a graph – https://www.puppygraph.com/
Devon:
Fortunately uhh I don’t think anyone in our team is named Devon, but this video has been making its rounds the Internet as the first ‘AI software engineer’
https://www.youtube.com/watch?v=fjHtjT7GO1c
Just remember, Devon hasn’t taken our jobs…. yet.